클릭하우스 업데이트는 왜 느릴까?
How we built fast UPDATEs for the ClickHouse column store – Part 1: Purpose-built engines
ClickHouse is a column store, but that doesn’t mean updates are slow. In this post, we explore how purpose-built engines like ReplacingMergeTree deliver fast, efficient UPDATE-like behavior through smart insert semantics.
clickhouse.com
클릭하우스 블로그 글에서 이론에 관한 부분만 요약해서 정리
Row vs Column Store 데이터베이스
Row Store (행 기반 데이터베이스, PostgreSQL, MySQL) 데이터베이스에서는 모든 행이 디스크에 연속적으로 저장되어 있음. 이러한 구조는 row 가 하나로 모여있기 때문에 업데이트가 쉬움. 하지만 일부 칼럼만 읽으려고 해도 모든 Row 를 읽어와야해 읽기 속도가 느림
Column Store (열 기반 데이터베이스, Clickhouse) 데이터베이스는 모든 열이 별도의 파일로 분리되어 있음. 이런 구조는 열이 분리되어 있기 때문에 필요한 칼럼만 읽으면 돼서 읽기 속도가 빠르다. 하지만 업데이트시 여러개의 파일에 동시에 접근해야하기 때문에 읽기가 쉽지 않다.
In row stores (like PostgreSQL or MySQL):
- Each row is stored contiguously on disk.
- This makes updates easy, you can overwrite a row in place.
- But analytical queries suffer: even if you need just two columns, the entire row must be loaded into memory.
In column stores (like ClickHouse):
- Each column is stored in a separate file.
- This makes analytics blazing fast, only the columns you query are read.
- But updates are harder because each column is stored separately, modifying a row means touching multiple files and rewriting fragments.
Insert 를 이용한 업데이트
업데이트가 어려운 칼럼형 데이터베이스 구조 때문에 클릭하우스는 개별 데이터를 업데이트 하는 대신에 데이터를 추가하고 덮어쓰는 방식을 사용한다. UPDATE 쿼리를 날리는게 아니라 기존의 행과 거의 똑같고 일부 데이터만 다르게 넣어서 업데이트를 하는 방식이다. Insert 를 이용한 Update 사용시 전역 락업이 따로 없기 때문에 속도는 보장되며 백그라운드에서 일어나기 때문에 실제 사용과 완전히 분리된다.

The core idea is simple: ClickHouse is especially optimized for insert workloads. Because there are no global structures to lock or update (e.g., a global B++ index), inserts are fully isolated, run in parallel without interfering with each other, and hit disk at full speed (in one production setup, over 1 billion rows per second). This also means insert performance stays constant, no matter how large the table grows. Additionally, inserts stay lightweight: all the extra work, like resolving record updates, is decoupled and deferred to background merges.
테이블 엔진마다 업데이트 방식에 차이가 있다. 애플리케이션 환경에 맞게 취사 선택을 해주면 됨. 어차피 Upsert 를 이용한 방식이고 데이터가 있다면 덮어쓰는 방식을 사용한다는 점은 동일하다.
All three engines, ReplacingMergeTree, CoalescingMergeTree, and CollapsingMergeTree, support what is effectively an UPSERT (insert-or-update) operation: insert a new row, and if a match exists (by sorting key), the engine will apply the right logic to update.

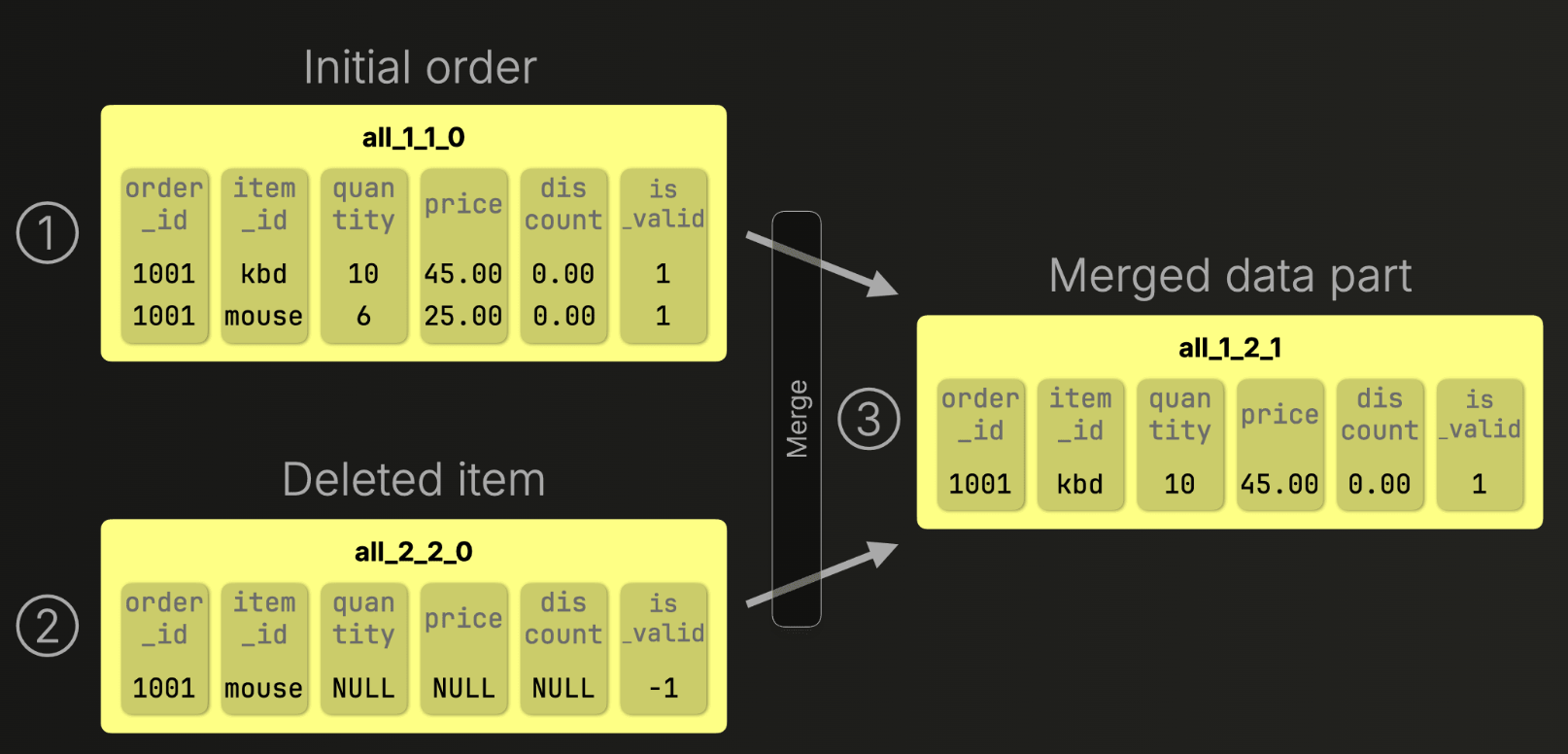
단점 및 보완
그런데 update 의 단점은 머지가 언제 끝날지 모른다는거. 백그라운드에서 머지가 되기 전까지는 기존 데이터와 업데이트 데이터가 공존하고 있고 로드할 때도 데이터가 중복으로 보일 수 있다.
All three engines described above use merges to consolidate data in the background. That makes insert-based updates and deletes highly efficient, but also eventually consistent: merges may lag behind when ingest is heavy (i.e., merges run continuously, but inserts may outpace them, think of it as a lagging consolidation window).
최근 업데이트에서는 Patch Part 라는 걸 이용해서 업데이트를 시각적으로도 빨리 보여주게 만들었는데 다음 포스트에서는 이것도 다뤄봐야겠다.