-
클릭하우스 업데이트 빠르게 만들기개발/데이터베이스 2025. 10. 3. 10:19
클릭하우스 업데이트는 왜 느릴까?
How we built fast UPDATEs for the ClickHouse column store – Part 1: Purpose-built enginesClickHouse is a column store, but that doesn’t mean updates are slow. In this post, we explore how purpose-built engines like ReplacingMergeTree deliver fast, effi
selfish-developer.com
지난 포스트에서 클릭하우스 업데이트가 느린 이유를 설명했고 이번 포스트에서는 업데이트 속도를 올리기 위한 클릭하우스의 트릭(?) 여러가지를 소개함. 이것도 클릭하우스 블로그 글을 읽어보고 중요한 부분들만 요약 발췌했다 .
기존 업데이트 방식
업데이트가 발생하면 클릭하우스는 뒤에서 mutation 을 실행하고 세가지 단계로 진행된다.
1. 업데이트에 대해서 새로운 block number 가 발행됨
2. mutated part 가 디스크에 저장되고 새로운 버전이 된다
3. mutation 은 기존 버전보다 낮은 part 에 대해서 적용된다.

업데이트된 칼럼에 대해서는 새로운 part 랑 링크가 추가되고 그렇지 않은 컬럼에 대해서는 hard linked 로 관리된다. 이런 작업이 백그라운드에서 진행되며 최종적으로 mutation 이 끝나고나면 데이터가 visible 하게 된다.
On the Fly updates
업데이트 결과물을 빠르게 보기 위한 방법. 실제 데이터가 rewrite 되기 전에 업데이트를 보여주게 된다.
To reduce the latency between issuing an UPDATE and seeing the result, ClickHouse introduced on-the-fly mutations, an optimization that makes updates visible immediately, even before any part is rewritten.

업데이트 결과물을 메모리에 저장하고 데이터를 로딩할 때 메모리를 거쳐서 가져간다. 이렇게하면 mutation 완료 전에도 데이터를 빠르게 볼 수 있다는 장점이 있지만 백그라운드 rewrite 작업을 피할 수 없고 update 데이터 양이 많으면 속도가 느려질 우려도 존재한다. 메모리 공간도 유한하기 계속 의지할 수 없기도 하다.
Patch part
블로그에서 중점적으로 설명하는 기술. fast insert 랑 백그라운드 머지 방법을 generalize 해서 사용하는 방식임
Patch parts borrow two proven ideas from our specialized engines, fast inserts and background merges, and generalize them, fully encapsulated for flexible, SQL-style updates:
기존 mutation 과 다르게 클릭하우스가 전체 칼럼 part 를 재작성하는게 아니라 수정된 부분에 대해서만 patch part 를 만듬
Unlike classic mutations, ClickHouse doesn’t rewrite the entire column or part. Instead, it creates a new, compact patch part that contains only:
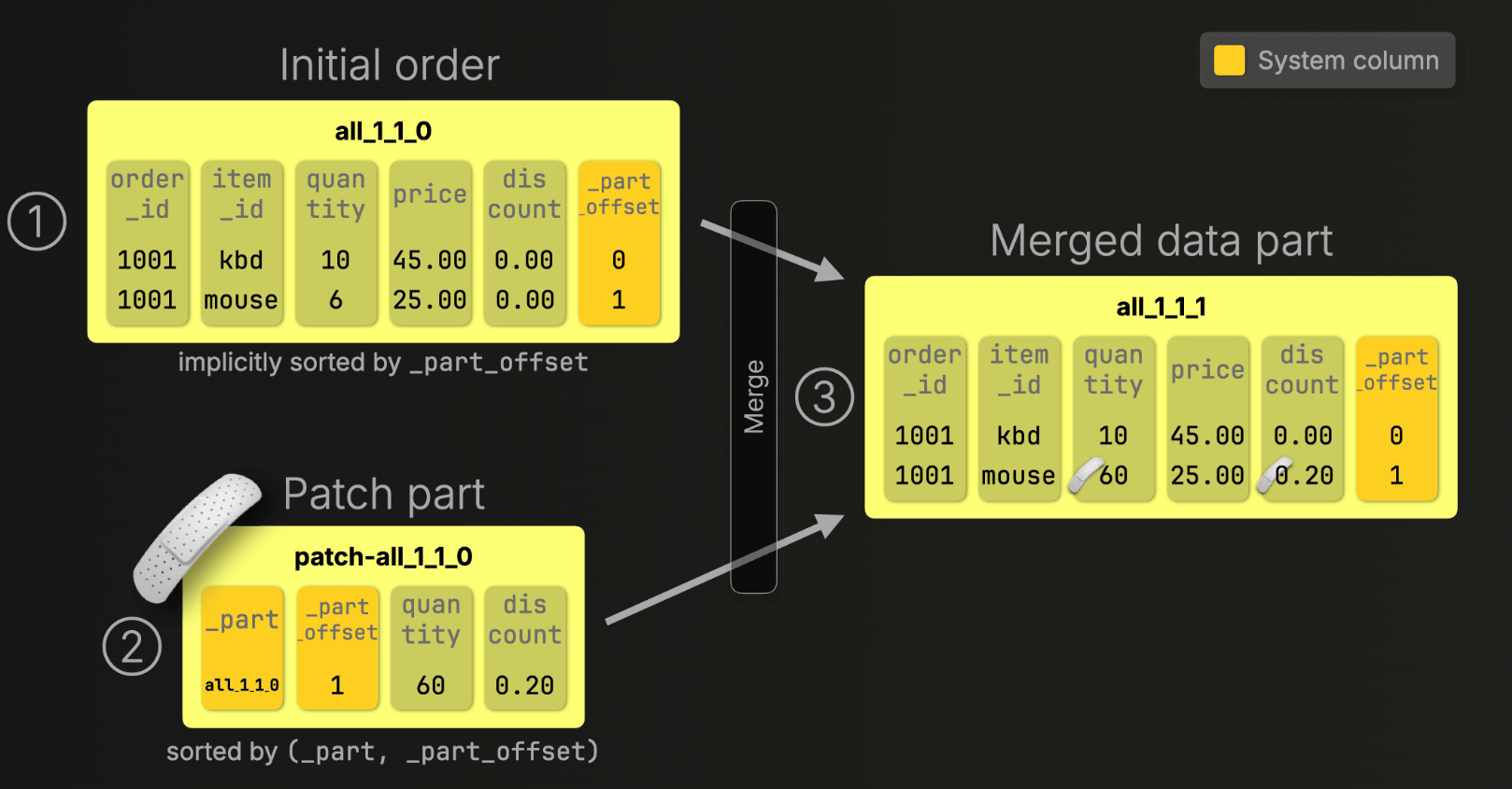
Patch part 는 백그라운드에서 진행하는 작업에 편승하는 작업이며 오버헤드는 거의 없다
Patch parts piggyback on merges already happening in the background, they hook into the process ClickHouse already runs continuously, with almost zero overhead:
시스템 칼럽 (_part offset, _block_offset) 을 활용해서 정렬 작업을 최적화한다. 기존 데이터와 Patch part 데이터가 호환이 잘 될수 있도록 만들기 위한 작업인듯

patch part 로직을 활용하기 위해 모든 행은 세가지 시스템 칼럼을 사용한다. 칼럼을 이용해서 merge 시 인덱싱 속도를 높이는데 자세한 내용까지는 알 필요는 없을 것 같고 필요하다면 여기 읽어보기

업데이트 자체는 merge 를 기다리지 않는 non blocking 방식임: 백그라운드에서 merge 가 진행 되더라도 외부에 보여주는 데이터 자체는 이미 머지가 진행된 상태. 기존 방식에서는 백그라운드 머지가 완료된 상태여야 했다. 각각의 업데이트는 업데이트가 시작될 때의 데이터 스냅샷 기준으로 실행된다.
ClickHouse updates are non-blocking: they don’t wait for merges to finish. Instead, each update runs against a snapshot of the parts that exist when the UPDATE begins.
Featherweight Deletes
삭제 작업에서도 동일한 로직을 적용할 수 있다. Patch Part 방식처럼 삭제가 적용되는 일부 row 에다가만 업뎃을 해준다. 그래서 삭제 작업은 더이상 ALTER 명령이 아니게 된다
In Stage 1.5, lightweight DELETEs already gave us a win: they rewrote only the _row_exists deletion mask via an ALTER UPDATE, avoiding full-row rewrites.
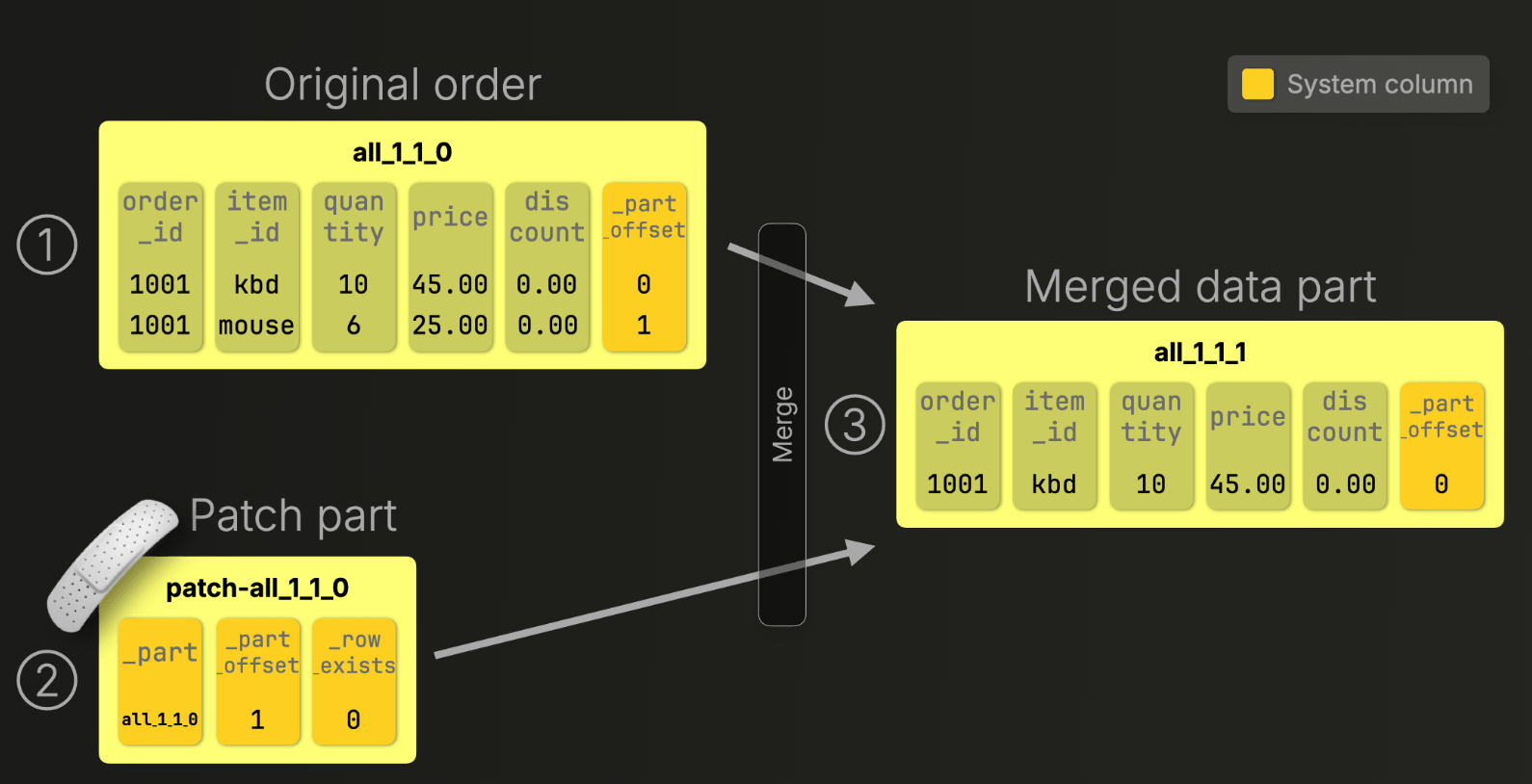
Patch part 에서 _part_offset 1 에 해당하는 row 에 대하여 _row_exists = 0 으로 설정했고 Merged 일 때 mouse 가 삭제된 체로 업데이트 되는것을 확인할 수 있다.
How patch-on-read works
성능에 미치는 영향을 최소화해서 만들었다고함.

쿼리에서 고른 데이터는 날짜에 따라서 여러개의 data 영역 (data range) 으로 나눠짐. 요 영역들은 쿼리 엔진에 따라서 별개의 parallel stream stages 로 나눠지고 병렬 처리 절차를 따르며 결과가 나오게됨
Usually, the data selected for a query (after index analysis) is located in several data ranges (consecutive blocks of rows) in several data parts. These ranges are dynamically spread by the query engine across ① separate and parallel stream stages (data streams) and then processed by ② parallel processing lanes that filter, aggregate, sort, and limit the data into its final result:
Patch Part 는 특별한 요소처럼 보이지만 결국에는 클릭하우스 regular part 의 일종이며 다른 patch part 와 최종적으로 머지됨.
위와 같은 테크닉을 써서 성능에 영향을 미치지 않았다고 하지만 실제로 이렇게 동작하는지는 주의깊게 살펴볼 필요는 있다고 생각함.
Patch parts may seem special, but under the hood, they’re just regular parts in ClickHouse. That means:
- They are merged with other patch parts using the ReplacingMergeTree algorithm, with _data_version as a version column. This ensures each patch part stores only the latest version of each updated row.
- They’re automatically cleaned up once their changes are fully materialized into all affected data parts, or when merged with another patch part. Background cleanup threads handle this safely.
- They count toward the TOO_MANY_PARTS threshold, which applies per partition. To mitigate this, patch parts are stored in separate partitions based on the set of updated columns. So if you run multiple UPDATE statements that affect different columns, like SET x = …, SET y = …, and SET x = …, y = …, you’ll get separate patch partitions, each with its own part count.
This design keeps patch parts fast, efficient, and deeply integrated with MergeTree mechanics.
part 가 늘어나면 일반적으로는 읽어야할 파일의 수가 늘어나기 때문에 성능에 무리가 가게 될텐데 업데이트가 많아질수록 patch part 데이터가 늘어나면서 문제가 생길 수 있는게 아닐까 싶다.
'개발 > 데이터베이스' 카테고리의 다른 글
Clickhouse Skip Index (0) 2025.11.07 Clickhouse JSON 칼럼 (0) 2025.10.27 클릭하우스 업데이트는 왜 느릴까? (0) 2025.09.13 citus - 스키마 정리하고 분산테이블 만들기 (1) 2024.09.05 Sentry 에서 Clickhouse 를 택한 이유 (0) 2024.08.20